Wondering if dropout is a good option for your network? Dropout regularization is a great way to prevent overfitting and have a simple network. Overfitting can lead to problems like poor performance outside of using the training data, misleading values, or a negative impact on the overall network performance.
You should use dropout for overfitting prevention, especially with a small set of training data. Dropout uses randomness in the training process. The weights are optimized for the general problem instead of for noise in the data. It can cause slow training or missed trends if not used correctly.
If you want to learn how you can get the best out of dropout and avoid the common drawbacks, you are in the right place. Let’s get started and learn everything about dropout!
Should You Use Dropout?
Table of Contents
Neural networks with thousands or millions of parameters are very common nowadays and are quite powerful in machine learning systems. However, overfitting is a problem that is frequently faced. How can you prevent overfitting in your networks? First, let’s understand how overfitting happens.
Having a big network with less training data, or a smaller network that has trained for many epochs can cause overfitting in the network. Essentially, the optimizer has over-optimized the weights for a local minimum. The goal is for the optimizer to generalize to the global minimum (to get the lowest loss score) and therefore generalize the problem.
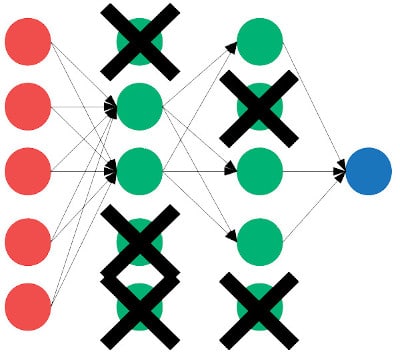
Dropout is a term that means you randomly abandon nodes in the network on each training pass. The nodes that are ignored are chosen on a random basis during the training phase. The result is the weights for nearby nodes are not adjusted at the same time. This decoupling makes the weight changes not correlate to each other and therefore ignore more noise.
Why Use Dropout?
Here’s the thing with overfitting:
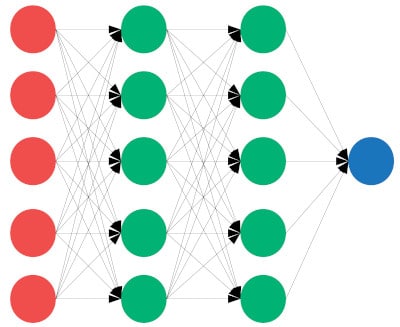
When a network is fully connected, the neurons are all depending on each other and lose their independence. During the training phase, the weight updates frequently happen to the same areas of the network at the same time.
With neural networks and machine learning, there are many regularization techniques. Regularization is the process of generalizing the network to prevent overfitting, so of course, dropout is one of these techniques. Dropout is a popular regularization technique that is supported by major python libraries like Keras and PyTorch. Later in this post, I will show you how to use dropout in PyTorch.
Dropped node is ignored in both forward and backpropagation. While dropout is used in training while adjusting the weights of the network, it should in no circumstances be used when the network is being used and evaluated. [1]
The learning algorithm doesn’t know which nodes are going to be ignored as the regularization is a random process.
Benefits of Using Dropout
Now that you know the basics of dropout, you might want to know how it benefits a neural network. After learning these benefits, you can decide if your neural network needs dropout or not. So, let’s get started!
No Overfitting
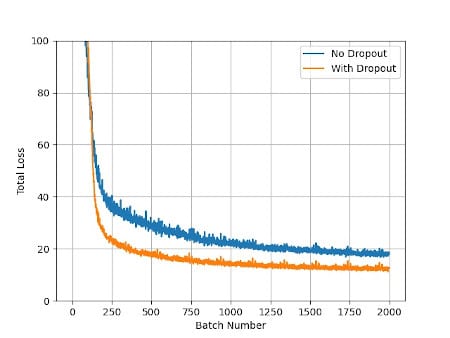
The main advantage of dropout is of course that it prevents overfitting. It is great for bigger networks where neurons are all connected. The regularization process of dropout makes the neurons independent of each other so that all of them can perform better with less noise.
Fewer Errors
Having less noise means fewer errors. This means that the output has amazing performance and great quality. This sounds like a great situation, doesn’t it?
It happens because when a random neuron is ignored for a single pass, the weight of the neuron becomes zero and it can’t cause an error. The average errors from different inputs become less overall causing a huge performance improvement in some cases.
Robust Model
Dropout makes the network ignore more noise and makes the model robust for that particular training phase. Having a robust model with fewer errors is a great situation to have in a neural network.
Having a training data set that is large enough to properly train the network is an important factor. Want to learn more about quickly increasing the size of your training data set? Check out my complete post about Data Augmentation!
Sparse Activation
Sparse activation means that less than half of neurons in the network have a non-zero output. Some networks get sparse activation due to dropout. The neural network is forced to learn a representation in a better and more efficient way. Sometimes, this is a side-effect of using dropout and an added benefit because it adds a desirable characteristic to the network.
| Network Layer | Best Dropout Rate |
|---|---|
| Input Layer | 0.8-0.9 |
| Intermediate/Hidden Layer | 0.5-0.8 |
| Output Layer | 1.0 |
Disadvantages of Using Dropout
As dropout has so many benefits, it must have adverse side effects. There are disadvantages of using dropout that may or may not degrade the performance of the network. Let’s find out some disadvantages so that you can weigh the tradeoffs for your specific situation.
Requires Separate Tuning
Dropout has an associated parameter that is the probability the weight is set to zero for the given training data. This parameter could be chosen for the network, layer by layer, or neuron by neuron. Generally, more parameters require more training and testing to find the optimal settings.
If the rate of dropout is too low, there won’t be any improvement in the performance, however, the negatives of dropout will be present without the benefits. If the rate is too high or too low, it can negatively impact the outcome.
Slow Convergence
When the dropout rate is higher than it should be, the convergence rate can become slow and training takes a long time. The weights are not adjusted by the optimizer fast enough because when new information is presented by the training data, the important components are missed and require more epochs.
Risk of Omitting Important Data Trends
In some applications like time-series data, single samples or small groups could contain critical information or data trends. Sometimes, dropout can cause important training data to be missed. In these cases, the nodes that were dropped needed to be adjusted based on the unique info in that sample of data.
This can happen if the dropout rate is too high for the problem being studied. It will lead to poor performance and loss of essential information on a random basis.
Using Dropout in PyTorch: nn.Dropout
Using dropout in PyTorch is very easy. For the network model you are designing, you can easily add dropout to the layers you need, and adjust their dropout rate separately. [3] First, let’s define the model:
import torch.nn as nn
class MyMLP(nn.Module):
def __init__(self):
super(MyMLP, self).__init__()
self.flat = nn.Flatten()
self.lin1 = nn.Linear(32 * 32, 64)
self.drop1 = nn.Dropout(p=0.5)
self.relu1 = nn.ReLU()
self.lin2 = nn.Linear(64, 32)
self.drop2 = nn.Dropout(p=0.5)
self.relu2 = nn.ReLU()
self.lin3 = nn.Linear(32, 5)
def forward(self, x):
y = self.relu1(self.drop1(self.lin1(self.flat(x))))
y = self.relu2(self.drop2(self.lin2(y)))
return self.lin3(y)
In this model, the dropout layers have a parameter p, which is the dropout rate. This is the probability of retaining the node (not set to zero). For p=0.5, there is a 50% chance the node is dropped.
Next, we need to remember to disable dropout when training is finished and we go to use the network. Fortunately, this is handled in PyTorch automatically. Several library features are enabled in training and disabled when using the network.
When training, call module.train(), and when running (evaluating the network) call module.eval():
net = MyMLP()
net.train()
for epoch in range(5):
for batch_num, (x, label) in enumerate(training_loader):
...
and using torch.no_grad() will disable the gradient calculation.
net = MyMLP()
net.eval()
with torch.no_grad():
output = net(input).cpu()
Dropout in Convolutional Neural Networks
For CNNs, there is a separate 2D form of dropout. If the regular method of zeroing random neurons were used with a CNN it would mean that information is still passed to the output.
This happens because of the 2D filter that is being used in the convolution process. When the matrix multiplication happens, the output is not zero. [2]
PyTorch’s nn.Dropout2d:
In PyTorch, the object torch.nn.Dropout2d is used in place of the usual torch.nn.Dropout:
import torch.nn as nn
class MyCNN(nn.Module):
def __init__(self):
super(MyCNN, self).__init__()
self.conv2d = nn.Conv2d(3, 32, 9, 1)
self.drop1 = nn.Dropout2d(p=0.5)
self.relu = nn.ReLU()
def forward(self, x):
y = self.relu(self.drop1(self.conv1(x)))
return y
Just like with the 1D calls in PyTorch, by calling Module.train() the dropout will be enabled (for training), and by calling Module.eval() the dropout will be disabled (for evaluation).
Tips for Dropout Regularization
If you want to use dropout in the best possible manner and without any risk of losing data, follow the tips given below:
- For LSTMs, use a different rate of dropout for the input. You can use dropout for any type of neural network as it isn’t bound for one type.
- Use a large dropout rate for input layers such as 0.8 or 0.9 (high rate of data retention).
- For hidden layers, the ideal dropout rate is 0.5.
- As dropout causes thinning of the neurons, only use it for a larger network. If you use it for a smaller network, it won’t work as well.
- Instead of applying a single dropout rate by guessing, use different rates and check the performance.
- For large datasets, dropout regularization isn’t ideal. Use it when the training data is limited.
One famous example of a network using Dropout is when researchers trained the VGG network.
The researchers trained the network on multiple GPUs for a week using millions of images.
Dropout was used during the training process to prevent overfitting. Want to learn more about the famous VGG network? Check out my post about why VGG is so commonly used!
Frequently Asked Questions
Want to check out some style transfers that were made using these concepts?
- Express yourself with the Van Gogh Style Guide.
- Go on an abstract adventure with the Jackson Pollock Style Guide
- Get an impression of Monet’s masterpieces in the Monet Style Guide
- Take a Rothko Retrospective with the Mark Rothko Style Guide
- Journey through the symbolic depths with Frida Kahlo’s Style Guide
- Discover Dali’s surreal style with the Salvador Dali Style Guide
Want to learn more about how style transfers and neural networks work?
Final Thoughts
Now you know that you can use dropout to prevent overfitting in your neural networks. There are some cases where dropout shouldn’t be used, but now you are well equipped to decide for your specific needs. If you use dropout by following the right methods, you can gain a lot of benefits and a well-performing network.
For more information on other types of neural networks, check out our tutorial on Bayesian Neural Networks and how to create them using two different popular python libraries.
Want to see an overview and the history of style transfers? Check out my post on Style Transfers, Neural Networks, and Digital Art!
Check out some other posts in the Style Transfer Category to learn more on this stellar topic.
Get Notified When We Publish Similar Articles
References
- Srivastava, Nitish, et al. “Dropout: a simple way to prevent neural networks from overfitting.” The journal of machine learning research 15.1 (2014): 1929-1958. Retrieved April 8, 2022, from https://www.cs.toronto.edu/~rsalakhu/papers/srivastava14a.pdf
- Tompson, Jonathan, et al. “Efficient object localization using convolutional networks.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2015. Retrieved April 8, 2022, from https://openaccess.thecvf.com/content_cvpr_2015/papers/Tompson_Efficient_Object_Localization_2015_CVPR_paper.pdf
- Dropout. Dropout – PyTorch 1.11.0 documentation. (n.d.). Retrieved April 8, 2022, from https://pytorch.org/docs/stable/generated/torch.nn.Dropout.html
